
İçinde bulunduğumuz dijital dönüşüm çağında insanların internette geçirdiği süre arttıkça web sitelerinde biriken veri miktarı da artıyor. Bir çok web sitesinde big data (büyük veri) dediğimiz devasa miktarda veri üretiliyor. Üretilen bu verilerin büyük bir kısmı dağınık, tek başlarına anlamsız ve yapılandırılmamış halde bulunuyor. ElasticSearch, büyük verilerin yönetimi için ortaya çıkmış bir çözüm yöntemidir. Eğer büyük veri blokları arasında metin arama gibi bir ihtiyacımız varsa, bu durumda ElasticSearch bizim için doğru bir tercih olabilir.
ElasticSearch nedir?
Genellikle tam metin arama, sorgulamalar, öneriler, veri analizi, iş analitiği ve operasyonel zeka kullanım örnekleri için tercih edilen Java dili ile geliştirilmiş, "Lucene" altyapısı üzerine oturtulmuş open-source bir arama motorudur.
ElasticSearch Visual Studio .NET tarafında NuGet kütüphanelerinden NEST ve Elasticsearch.net ile kolayca implemente edilebilmektedir. Restful API üzerinden hizmet verdiği için tüm programlama dilleri ile kullanılabilmektedir. Hem Windows Hem Linux’da kolayca çalışabilir.
ElasticSearch nasıl çalışır?
ElasticSearch text üzerinden doğrudan arama yapmak yerine, indexler üzerinden arama yapar ve çok hızlı bir şekilde sonuçlar üretir. ElasticSearch’e herhangi bir veri kaydedilirken, veri içerisinde daha önceden belirlenen alanlar indekslenir. ElasticSearch, bu işlemi veri kaydının ilk anında gerçekleştirdiği ve verileri indeks listesine göre sınıflandırdığı için, arama sonuçlarına hızlıca ulaşabilir. İlgili keyword aranırken bu büyük veri kümesi içerisinde değil, oluşturulan index listesi içerisinde arama yapılır.
Aşağıdaki örnek görselde belirtildiği gibi "blue sky" kelimesini aradığımızı varsayalım. "blue" kelimesinin 1, 2 ve 3, "sky" kelimesinin 2 ve 3 numaralı dokümanlarda geçtiğini görüyoruz. Yapılan index eşleştirme sonucunda "blue sky" kelimesi için index listesi üzerinden hızlıca 3 sonucunu elde ederiz.
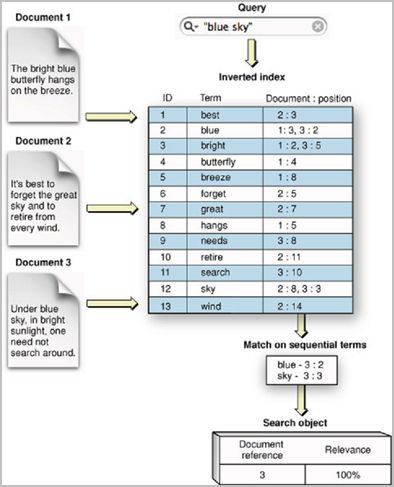
Image Source: https://tutorialseye.com/wp-content/uploads/45c1c4b1857b049834c2412b0dc8d256.png
Temel ElasticSearch kavramları nelerdir?
Index / Indice: Klasik arama motorlarında veri tabanları üzerinden arama gerçekleştirilirken, ElasticSearch aramaları "Indice " olarak adlandırılan indeks dosyaları üzerinden gerçekleştirilir. ElasticSearch üzerinde veri indekslenerek json formatında tutulur. Yani indexler, Json belgeler topluluğudur. Default veya Custom olarak yaratılabilirler. İndex bir çeşit veritabanıdır.
Type: Veritabanı yönetim sistemlerinde kullandığımız tablolar gibi düşünebiliriz. (Ör: e-ticaret sistemleri için ürünler, kategoriler, log bilgileri gibi verilerin her birini bir type olarak düşünebiliriz.) Bir index içerisinde birden fazla type barındırabiliriz.
Mapping: Verileri indexlerken bu verilerin hangi tipte olduğunu göstermemiz gerekir. Yani bir kelimeyi indexlerken o kelimenin hangi veri tipinde (string, integer, boolean) olduğu bilgisinin tanımlandığı işlemdir. Amacı, ilgili dokümanın arama motoruna nasıl aktarılacağının tanımlanmasıdır. Kısaca veritabanında isimlendirdiğimiz bir schema’dır diyebiliriz.
Document: ElasticSearch’deki her bir kayda, yani row’a (satır) document denir. Her type, birden fazla document’a sahiptir.
Field: Her bir doküman içindeki alana, field denir. Yani DB’deki bildiğiniz column. Klasik veritabanlarındaki Column’lar, Elasticsearch’te Field (Alan/kolon) olarak nitelendirilir. Her document bir den fazla fileld’a sahiptir.
Cluster: Bir veya daha fazla düğümün bir koleksiyonudur. Cluster, tüm veriler için toplu dizin oluşturma ve arama yetenekleri sağlar. Tüm verilerinizi bir arada tutan ve tüm indexleme ve arama yeteneklerinin yürütüldüğü birden çok node’dan oluşan bir küme veya node koleksiyonu şeklinde adlandırılabilir.
Node : Tek bir server’a verilen isimdir. Verilerin depolandığı makinelerin her biridir. Clusterların indeksleme ve arama yetenekleri bu nodelar sayesinde gerçekleşir. Tek fiziksel ve sanal Sunucu; RAM, depolama ve işleme gücü gibi fiziksel kaynaklarının yeteneklerine bağlı olarak birden çok düğüm barındırır.
Master Node: Master node aynı cluster altındaki tüm nodeların masterı gibi çalışır. Master node index yaratma, silme ve tracking etme gibi işlemlerden sorumludur.
Master Eligible Node: elastik searchteki bir property true seçilirse eligible node master node olarak ayarlanır. Eğer ki master nodumuzun olduğu server fail olursa master eligible nodelar çalışır.
Data node: Datayı tutar ve data ile ilişkili operasyonları yürütür. CRUD, SEARCH ve AGGREGATİONS
Ingest node: Gerçek indekslenme meydana gelmeden önceki işlemleri gerçekleştiren doküman
Tribe Node: Birden fazla clusteri bağlar ve bağlı clussterlar arasındaki search ve operasyonları yönetir.
Shard: Tek seferde milyonlarca dokumanı indexlemek için yeterli donanıma/server kapasitesine sahip olmayabilir. Tek seferde 2TB lık veriyi indexlemek zorunda kaldığınızı varsayalım, bu durumda bu indexlemeyi tek bir node ile yapmak istediğinizde, disk kapasitesinin dolması veya aşırı yavaş bir indexleme hızı ile karşı karşıya kalabilirsiniz.
Bunun önüne geçmek için Shard ve Replika kavramları bulunmaktadır.
Yapılacak olan bir index, bir node da yeniden shardlara bölünür. Bu shardları kendinize göre ayarlaya bilmektesiniz.
Shardlı mimarinin kullanılmasındaki temel amaçlar;
Birden fazla node üzerinde işlemleri dağıtımınızı ve paralelleştirmenizi sağlar. Böylece performans artar.
İçerik hacmini yatay olarak bölme ve ölçeklendirmeye olanak sağlar
Replica: Shard’ın devre dışı kalması ihtimaline karşı index shard’larının bir veya birden çok kopyasının oluşturulabilmesini sağlayan replica-shard yapısı bulunur. Tamamen güvenlik amaçlı çalışan, her verinin bir kopyasının bulunduğu başka makinelerdir. Böylece bir makine çöktüğünde replica veya replicalarından biri devreye girebilecektir. Örneğin aşağıda 3 Node’lu 3 Shardingli bir yapı söz konusudur. Ve her bir shard’ın 1 yedeği, yani 1 replicası bulunmaktadır. Sonuçta aşağıdaki örnekde 3 Node,3 Shard ve 1 Replica mevcuttur. Toplamda 6 sunucu bulunmaktadır.
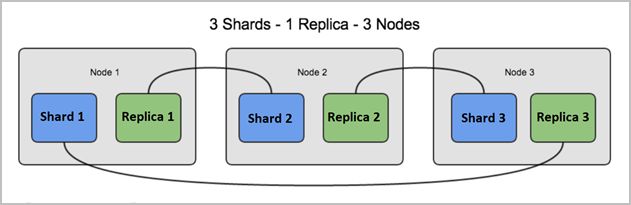
Image Source: https://elastic-stack.readthedocs.io/en/latest/_images/elk_cluster_shard.png
Bir shard’a ait replica, aynı node’da barındırılmamalıdır. Bir node çöktüğünde o node’daki shard(lar)’ın yedeklerinin diğer nodelarda bulunması veri kaybını önlemek için şarttır.
ElasticSearch avantajları nelerdir?
-
Açık kaynaktır.
-
Text üzerinden doğrudan arama yapmak yerine, indexler üzerinden arama yapar ve çok hızlı bir şekilde sonuçlar üretir. Gerçek zamana yakın bir hızla çalışır.
-
Dokümanları Restfull API üzerinden JSON formatında indexlemesi bir çok dil tarafından ortak kullanılabilirlik sağlar.
-
Otomatik Mapping ile veri tipine uygun biçimde bir dokümanın arama motoruna nasıl aktarılacağı tanımlanabilir.
-
Dağıtık ve yüksek ölçeklenebilir yapıda çalışabilir.
-
Otomatik tamamlama özelliği vardır.
-
Çoklu dil desteği vardır.
-
HBase, Cassandra, MongoDB gibi NOSQL veritabanlarından ElasticSearch’e aktarım yapılabilir.
-
Alternatiflerine göre çok az kaynak kullanarak çalışır.
-
Kolay bir şekilde yedekleme yapılabilir.
-
Elasticsearch’ü monitör edebilen Kibana ve log barındırmak için Logstash araçları ile birlikte kullanılabilir.
-
Gateway konseptlerini kullanarak backup yaratmak oldukça kolaydır.
-
Cluster yapıya sahiptir ve cluster yapısı oldukça basittir.
-
Hızlı kurulum ve kolay konfigürasyon